영속성 관리
JPA는 DB에 반영하는 방식이 다음과 같다. 먼저 JPA는 트랜잭션이 필수이다. 트랜잭션이 시작한 다음 JPA문, 예를 들어 persist같은 JPA구문 실행 시 바로 DB에 반영하는 것이 아니라 1차 캐시 저장소에 먼저 저장한다. 1차 캐시 저장소에 저장을 하고 트랜잭션이 끝나기 전에 조회를 하면 먼저 1차 캐시에서 조회를 한다음 없다면 DB에서 조회한다. DB에는 트랜잭션 커밋 시 1차 캐시에 반영된 내용을 일괄 DB에 반영한다.
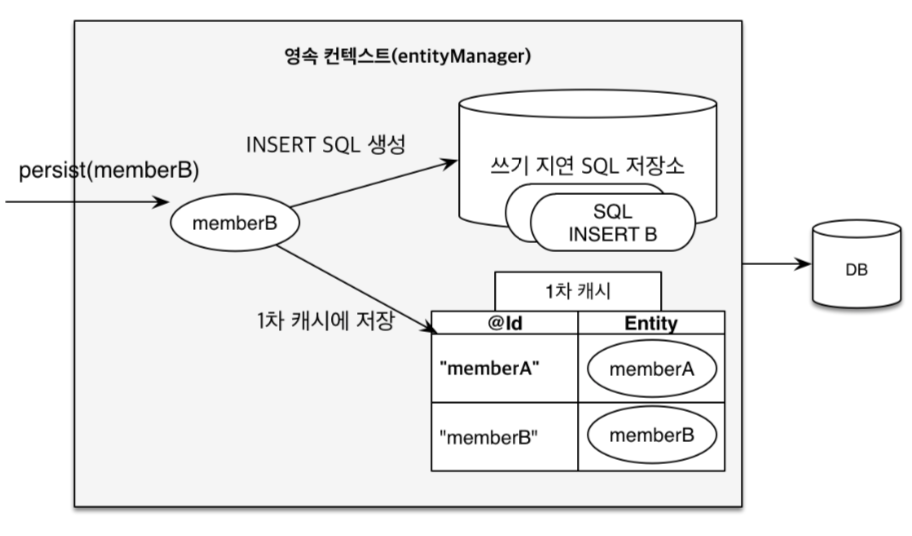
전에 회사에서는 JPA대신 MyBatis를 사용했었다. 그래서 트랜잭션을 걸어도 DB에 값이 반영되거나, 오류가 생기는 경우가 잦았는데 JPA는 그런점에서 신뢰감이 더 가는것 같다.JPA는 수정기능 사용 시 MyBatis보다 더 큰 이점이 있다.Mybatis는 update시 필요한 SQL문 만큼 쿼리문을 작성하고 그만큼의 코드 또한 작성을 해야해서 쿼리문에 의존하게 되는 경향이 강하다. 하지만 JPA는 다르다.Dirty Checking라는것을 이용한다. 다음 그림을 보자.

JPA는 1차캐시에 각 Entity의 최초상태를 복사한 스냅샷을 가지고있다. 트랜잭션 커밋 시 기존의 스냅샷과 달라진 Entity가 있다면 UPDATE구문을 생성해 DB로 날린다. 순서대로 분석해보면
1. 트랜잭션을 커밋하면 엔티티 매니저 내부에서 먼저 플러시가 호출된다.
2. 엔티티와 스냅샷을 비교해서 변경된 엔티티를 찾는다.
3. 변경된 엔티티가 있으면 수정 쿼리를 생성해서 쓰기 지연 SQL 저장소에 보낸다.
4. 쓰기 지연 저장소의 SQL을 데이터베이스에 보낸다.
5. 데이터베이스 트랜잭션을 커밋한다.
변경 감지는 영속성 컨텍스트가 관리하는 영속 상태의 엔티티에만 적용된다. 그리고 JPA의 기본 전략은 엔티티의 모든 필드를 업데이트 한다.
UPDATE MENBER
SET
NAME=?,
AGE=?
WHERE
ID=?가 아닌,
UPDATE MEMBER
SET
NAME=?,
AGE=?,
GRADE=?,
...
WHERE
id=?
이렇게하면 데이터 전송량은 늘어나지만 장점이 있다.
1. 모든 필드를 사용하면 수정 쿼리가 항상 같다. 따라서 애플리케이션 로딩 시점에 수정 쿼리를 미리 생성해두고 재사용 할 수 있다.
2. 데이터베이스에 동일한 쿼리를 보내면 데잉터베이스는 이전에 한 번 파싱된 쿼리를 재사용할 수 있다.